- 이 문서는 PENTAHO의 공식 document를 참고하였습니다.
- 버전은 가장 최신인 9.1 CE 기준으로 작성하였습니다.
- 저도 공부 중입니다.. 틀리거나 이상한 부분이 있으면 댓글 달아주셔요..^^
Memory GROUP BY STEP
[1] 설명
- 이 스텝은 일반적인 GROUP BY와 동일한 역할을 수행하는 STEP입니다.
- GROUP BY와 MEMORY GROUP BY의 차이점
[2] 사용 용도
테이블의 GROUP BY를 수행한다.
[3] 사용법 예제
우선 가장 먼저 데이터를 가지고 와 보도록 하겠습니다.
EMPNO,NAME,DEP,SALARY
1001,Park,Sales,8000
1002,Selle,IT,7000
1003,Joe,Marketing,4500
1004,Robert,Marketing,7800
1005,Janet,Sales,6600
1006,Jung,Marketing,6200
1007,Gully,Sales,9000
1008,Selen,Marketing,3200
1009,Kim,IT,11500
위 데이터는 txt 파일로 사원번호, 이름, 부서명, 연봉 순으로 칼럼을 가지고 있습니다. 이 데이터의 부서별 연봉이 가장 높은 값, 가장 낮은 값을 뽑아내어 보도록 하겠습니다.
로직은 다음과 같습니다.
- text file input : txt 데이터를 입력받는 역할을 수행하는 STEP
- Memory Group By : grouping을 설정하고, 부서별 연봉의 MAX, MIN값을 계산 설정하는 STEP
- dummy : 결과 확인 역할을 수행하는 STEP
text file input STEP
- 이 STEP은 txt 파일을 입력하는 역할을 합니다.
- 파일 또는 디렉터리 칸에 찾아보기를 눌러, 원하는 데이터를 입력하신 후, 그다음에 추가를 누르시면 그림과 같이 선택한 파일로 파일의 주소명이 옮게 가게 됩니다.

MEMORY GROUP BY
- 이 STEP은 GROUP BY를 수행하는 역할입니다.
- 그룹을 만들 필드라는 곳에 내가 GROUPING을 할 칼럼을 넣어주시고, 집계라는 곳에 새롭게 집계해서 나오는 데이터들의 칼럼명을 이름에, 계산을 수행할 칼럼명을 대상에, 원하는 계산을 데이터형에 기입해 주시면 되겠습니다.
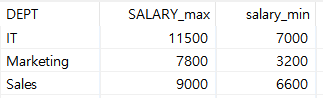
- 저는 DEPT(부서)를 GROUP BY 할 것이므로, 그룹 필드에 DEPT를 넣었고, 이름은 SALARY_MAX, salary_min으로 대상은 둘 다 모두 SALARY(연봉) 그리고 마지막으로 유형에 최댓값과 최솟값을 기입하였습니다.

DUMMY
- 이 STEP은 결과를 보기 위해 넣은 STEP입니다. 결과는 다음과 같습니다.
감사합니다.
'PENTAHO > STEP' 카테고리의 다른 글
| [PENTAHO] GROUP BY STEP (0) | 2021.07.19 |
|---|---|
| [PENTAHO] FILTER ROWS STEP (0) | 2021.07.15 |
| [PENTAHO] DATA GRID STEP (0) | 2021.07.15 |
| [PENTAHO] DUMMY STEP (0) | 2021.07.15 |




댓글