반응형
🎯 목표
- Spark가 왜 필요한지, 어떤 문제를 해결하기 위해 만들어졌는지 이해하기
- Spark의 내부 구조(Driver, Executor, Cluster Manager)가 어떤 역할을 하는지 파악하기
- 실행이 실제로 어떻게 이루어지는지, Job/Stage/Task 구조를 통해 흐름을 이해하기
- 실습보다는 개념 정리를 중심으로, 이후 실전 학습을 위한 기반 만들기
내용
전체 요약
- Spark는 분산/병렬 처리를 위한 프레임워크이다. 대용량 데이터를 여러 컴퓨터(노드)에 나눠 처리할 수 있게 설계되었다.
- 개발자가 작성한 코드는 Spark 내부에서 실행 계획으로 바뀌며, 그 계획을 바탕으로 Driver가 전체 흐름을 조율하고, Executor가 병렬로 작업을 수행한다.
- 이 모든 구조는 Cluster Manager 위에서 동작하며, 클러스터 환경의 자원을 효율적으로 관리한다.
상세
1. Spark는 왜 존재하는가?
현대의 데이터는 수백 GB, 수십억 건에 달하는 경우가 많다. 이런 데이터를 단일 컴퓨터에서 처리하는 것은 성능, 메모리, 시간 측면에서 비효율적이다.
Spark는 이런 문제를 해결하기 위해 등장했다:
- 데이터를 여러 조각(Partition)으로 나눔
- 각 조각을 서로 다른 컴퓨터에서 동시에 처리 (병렬 처리)
- 병렬 처리 후 결과를 모아서 최종 결과 도출
즉, Spark는 병렬 처리와 분산 처리를 자동화한 도구이다.
근데 언제부터 데이터가 "나눠진" 상태가 되는 거지?
Spark에서는 데이터를 읽는 시점부터 내부적으로 'Partition'이라는 단위로 쪼개진다고 한다. 이 Partition들이 나중에 각각의 노드(또는 Executor)로 분산돼서 병렬로 처리된다고 한다. 예를 들어 1GB짜리 CSV 파일을 Spark가 읽는다고 하면, 이걸 그냥 한 번에 들고 오는 게 아니라 내부적으로 적당한 크기(보통 수십~수백 MB)로 나눠서 여러 조각으로 만든다고 한다.
이 조각 하나하나가 Partition이 되는 거고, Spark는 이걸 기반으로 Task를 만들어서 Executor에 분산시킨다. 만약 클러스터 환경이라면 Partition 단위로 데이터를 여러 머신에 나눠 보내고, 로컬 환경이라면 여러 CPU 코어에 병렬로 보내는 식이다.
결국 사용자가 .read.csv() 같은 코드 한 줄만 써도, Spark는 알아서 데이터를 나누고, 나눠진 조각을 Executor들이 병렬로 처리할 수 있게 준비해 둔다는 거다. 그래서 명시적으로 "이 데이터를 나눠라"라고 안 써도 이미 분산 처리 준비가 끝나 있는 셈이다.
아니 그러면 분산 처리를 한다는데, 컴퓨터가 여러 대 있어야만 가능한 걸까?
꼭 그런 건 아니라고 한다. Spark는 개발용이나 테스트용으로는 내 컴퓨터 한 대에서도 병렬 처리처럼 동작시킬 수 있게 local 모드를 지원한다. 예를 들어 local[4]라고 하면, 내 컴퓨터에 있는 CPU 코어 4개를 병렬 처리 유닛처럼 활용해서 실행하는 방식이라고 한다. 이건 완전히 분산은 아니지만, 병렬 처리 구조를 체험하고 테스트하기에는 충분할듯..
AWS EMR, GCP Dataproc, 또는 Kubernetes 클러스터 위에 Spark를 띄워서 실행하는 방식이 그 예다. 이 경우 각 노드는 Executor로 동작하고, Driver가 이들을 제어하게 된다. 결국 개발 시점에는 로컬로도 충분하지만, 운영이나 실전 환경에서는 클러스터 리소스를 어느 정도 확보해야 분산 처리가 의미 있게 작동하는 구조다. 그리고 이때부터는 리소스 비용도 신경 써야겄네..
2. Spark의 기본 구조: 3대 구성 요소
Spark는 데이터를 병렬로 처리할 수 있게 하기 위해 세 가지 주요 구성 요소를 가지고 있다.
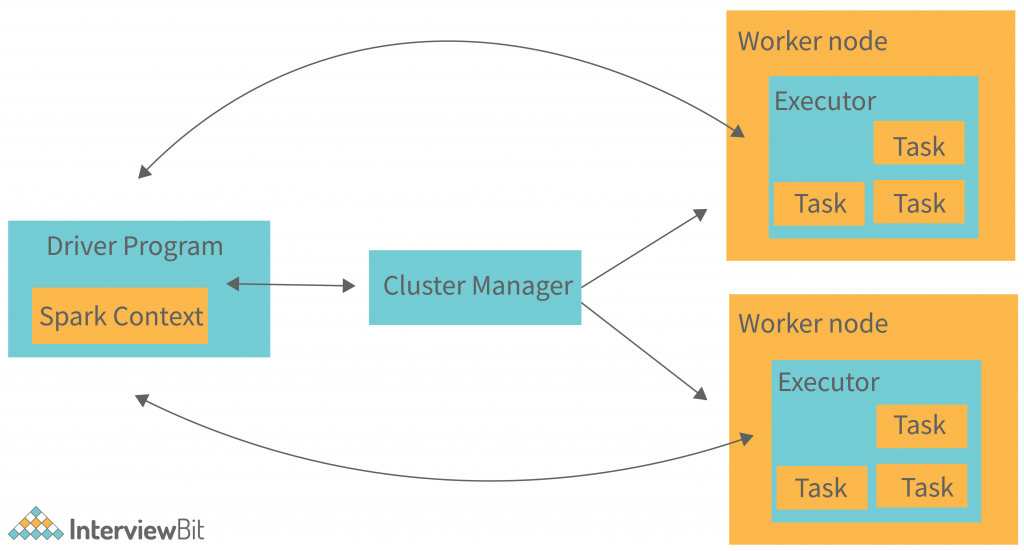
Driver
- Spark 애플리케이션의 시작점이자 두뇌
- 실행 계획(DAG)을 수립하고, Task를 나눠서 Executor에게 전달함
- 최종 결과를 수집하거나 저장함
Executor
- 실질적인 작업 수행자
- Driver로부터 받은 Task를 받아서 처리하고, 중간/최종 결과를 반환함
- 여러 개의 Executor가 병렬로 실행됨
Cluster Manager
- 클러스터 전체의 자원(CPU, 메모리 등)을 관리
- Driver의 요청을 받아 Executor를 배정함
- 종류: Standalone, YARN, Kubernetes 등
분산 처리를 한다는데, 컴퓨터가 여러 대 있어야만 가능한 걸까?
꼭 그런 건 아니라고 한다. Spark는 개발용이나 테스트용으로는 내 컴퓨터 한 대에서도 병렬 처리처럼 동작시킬 수 있게 local 모드를 지원한다. 예를 들어 local[4]라고 하면, 내 컴퓨터에 있는 CPU 코어 4개를 병렬 처리 유닛처럼 활용해서 실행하는 방식이라고 한다. 이건 완전히 분산은 아니지만, 병렬 처리 구조를 체험하고 테스트하기에는 충분할듯..
AWS EMR, GCP Dataproc, 또는 Kubernetes 클러스터 위에 Spark를 띄워서 실행하는 방식이 그 예다. 이 경우 각 노드는 Executor로 동작하고, Driver가 이들을 제어하게 된다. 결국 개발 시점에는 로컬로도 충분하지만, 운영이나 실전 환경에서는 클러스터 리소스를 어느 정도 확보해야 분산 처리가 의미 있게 작동하는 구조다. 그리고 이때부터는 리소스 비용도 신경 써야겄네..
3. 실행 방식 예시
개발자가 코드를 작성하면 아래와 같은 흐름이 된다:
from pyspark.sql import SparkSession
# 1. SparkSession 생성 (Driver가 실행 계획 수립 준비)
spark = SparkSession.builder \
.appName("ExecutionExample") \
.master("local[2]") \
.getOrCreate()
# 2. 데이터 로드 (아직 실행되지 않음 - Lazy)
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# 3. Transformation 연산 (계획만 추가)
df_filtered = df.filter("age > 30").select("name", "age")
# 4. Action 실행 (이 시점에 Job 생성되고 Executor들이 작업 시작)
df_filtered.show()
- spark.read.csv() 같은 코드를 Driver가 받음
- Driver는 실행 계획(DAG)을 생성함
- Cluster Manager가 Executor를 준비함
- Driver가 Task를 Executor들에게 분배함
- Executor는 병렬로 데이터를 처리하고 결과를 반환함
이 전체 과정은 사용자가 단순히 .show() 한 줄만 써도 내부에서 자동으로 일어난다.
내가 코드를 여러 줄 썼는데, Spark는 언제 진짜로 실행을 시작하는 걸까?
Spark는 Transformation(filter, select 등)을 작성해도 바로 실행하지 않고 DAG라는 실행 계획에만 저장해둔다고 한다. 실제 실행은 .show()나 .collect() 같은 Action이 호출되는 시점에 일어나서, 중간 작업들을 최적화해서 한 번에 처리할 수 있다고 한다.
4. Spark의 실행 단위: Job, Stage, Task
Spark는 .show(), .collect(), .write()와 같은 Action이 호출되는 시점에 비로소 실행을 시작한다. 이 실행은 다음과 같은 구조로 나뉜다:
- Job
- 사용자가 Action을 호출하면 Spark는 이를 하나의 Job으로 정의한다.
- 하나의 Job은 최종 결과를 얻기 위한 전체 작업 단위다.
- Stage
- Job은 내부적으로 여러 Stage로 나뉜다.
- Stage는 Shuffle이 발생하는 지점을 기준으로 분리된다.
- 예: filter는 Partition 내부 연산이므로 Shuffle이 없지만, groupBy나 join은 Partition 간 데이터 이동이 필요하므로 Stage가 나뉜다.
- Task
- Stage는 다시 여러 개의 Task로 쪼개진다.
- 하나의 Task는 하나의 Partition을 처리하는 단위이며, Executor가 이를 병렬로 실행한다.
예를 들어 아래 코드를 실행하면:
spark.read.csv("data.csv", header=True) \
.filter("age > 30") \
.groupBy("gender") \
.agg({"salary": "avg"}) \
.show()
Spark는 다음과 같은 구조로 실행한다:
- Job 1 생성 (show로 인해 트리거)
- Stage 1: filter (Shuffle 없음)
- Stage 2: groupBy + agg (Shuffle 발생 이후 처리)
Task는 각각의 Stage에서 생성된 Partition 개수만큼 병렬로 실행된다.
filter, groupBy, agg 이런 걸 계속 쓰고 있는데, 이게 각각 어떤 단위로 처리되는 거고 언제 나뉘는 걸까?
filter는 각 파티션 내부에서 독립적으로 처리할 수 있어서 shuffle이 없고, Stage가 나뉘지 않는다고 한다.
반면 groupBy는 같은 key 값을 가진 데이터를 한 곳으로 모아야 하니까 shuffle이 일어나고, 이 시점에 Stage가 나뉜다. agg는 groupBy와 함께 같은 Stage로 묶이는 경우가 많다고 한다. 흐음... 다음에 다시 하자..
다음 계획
- Spark에서 실제 데이터가 어떻게 쪼개지고, Partition과 Task로 분배되는지
- Shuffle이 발생하는 구조와 그 비용
- Stage와 Job, Task의 흐름을 시각적으로 이해하기 위한 DAG 구조 학습
참조
- Apache Spark Architecture Diagram: https://www.interviewbit.com/blog/apache-spark-architecture/
(출처 이미지: https://www.interviewbit.com/blog/wp-content/uploads/2021/04/Spark-Architecture.png)
{kind=link}
반응형
'Python > Spark' 카테고리의 다른 글
| Spark 독학하기 3일차 – 분산 처리가 뭐야.. (0) | 2025.05.11 |
|---|---|
| Spark 독학하기 0일차 – Spark를 공부해야겠구만.. (2) | 2025.05.10 |
| Spark 독학하기 1일차 – M1 맥에서 PySpark 환경 구성 및 테스트 (2) | 2025.05.10 |
댓글